MIMEOCXは、以下に示すOSで動作確認を行っております。
Microsoft Windows 95、Microsoft Windows 98、
Microsoft WindowsNT 4.0、Microsoft Windows 2000
Microsoft Windows XP、Microsoft Windows 2003
MIMEOCXをご使用いただくには、以下のいずれかのソフトウェアが必要です。
Microsoft
Visual Basic Ver 5.0
Microsoft Visual Basic Ver 6.0
Microsoft Office 2000 (Access、Excel)
| MIMEOCXは、Microsoft Visual C++ Ver 5.0で作成しています。サンプルは、Microsoft Visual
Basic Ver 5.0で作成しています。 ※ 本製品は日本語環境のみの対応となります。 |
製品のCD-ROMに含まれているセットアップキット(Willware.exe)をダブルクリックします。
画面にしたがって、インストールを進めて下さい。
1.インストールを始めます。「次へ」をクリックして下さい。
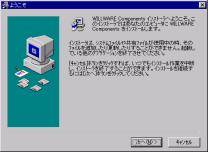
2.使用許諾契約書です。内容に同意される場合は「次へ」をクリックして下さい。
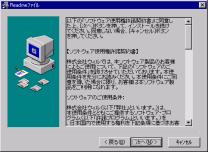
3.インストール先のフォルダを指定します。
初期設定でよろしければ「次へ」をクリックして下さい。
別のフォルダを指定したい場合は「参照」をクリックし、フォルダを指定して下さい。
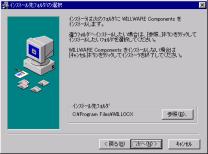
4.インストール中に置換されるファイルのバックアップを作成できます。
そのバックアップファイルの保存先フォルダを指定します。
初期設定でよろしければ「次へ」をクリックして下さい。
5.WILLWAREComponentsを登録するスタートメニュー又はプログラムマネージャのグループフォルダを指定します。
初期設定では、新規に「WILLWARE Components」の名前でフォルダを作成します。
特に指定する必要がなければ、初期設定をお勧めします。
6.プログラムのコピーを開始します。「次へ」をクリックして下さい。
7.プログラムのコピーをしています。中断する場合は、「キャンセル」をクリックして下さい。
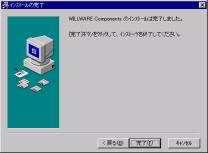
8.インストールが完了しました。「完了」をクリックし、インストールを終了して下さい。
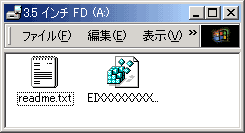
ライセンスを登録します。
製品に含まれているフロッピーディスクのレジストリファイル(EIXXXXXXXXX.reg)を
ダブルクリックして下さい。
(「XXXXXXXXX」は、任意の数字がファイル名として付けられています。)
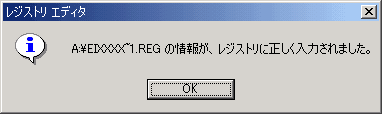
以下のメッセージボックスが表示され、ライセンスがレジストリに登録されます。
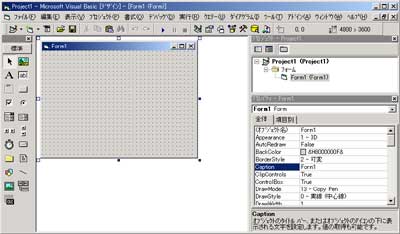
あらかじめ電子メールで通知しているライセンス情報を利用してライセンスを登録する等、レジストリファイルを利用しない場合は、VisualBasic起動後に新規プロジェクトを選択し以下のデザイン画面を開きます。 |
ツールボックスを右クリックしてメニューから「プロジェクト」を選択し、「コンポーネント」画面を開きます。次にコントロールタブの一覧からMIMEOCXを選択して「OK」をクリックすると、MIMEOCXがツールボックスに追加され、アイコンが表示されます。 |
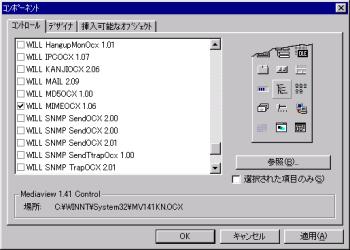
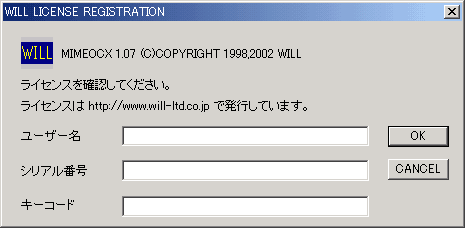
ツールボックスに追加されたMIMEOCXを選択し、フォームにアイコンを貼り付けると、以下の「WILL LICENSE REGISTRATION」画面が表示されます。ここで、ユーザー名、シリアル番号、キーコードをそれぞれ入力してライセンス登録を行います。 |
既にトライアルライセンスが登録されている場合には、デザイン画面にあるMIMEOCXのプロパティで「バージョン情報」をクリックして下さい。 |
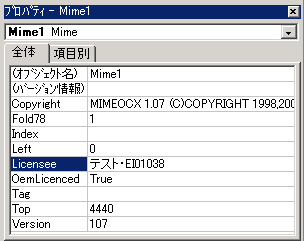
「WILL LICENSE REGISTRATION」画面が表示されますので、ここで正規ライセンスを入力して下さい。
※ライセンスが入力できない!?
※登録したライセンスを認識しない!?
※トライアルライセンスで作成したアプリケーションはどうする!?
|

「WILLWARE Components」の「サンプル」を起動すると「WILLWARE Components サンプル」画面が表示されます。サンプルの起動、またはそれぞれのソースを開くことができます。但し、ソースを開くにはライセンスが必要です。トライアルライセンス又は、正規ライセンスを登録してご利用下さい。(ライセンスの登録方法は前項の「ライセンスの登録」をご覧下さい。) |
サポート作業を円滑に行うために、お問い合わせの際には以下の情報をご用意下さい。
弊社ホームページの「サポート」のページで、キーワードを入力してFAQを検索できます。休業日などサポートの対応が遅れる場合もありますので、まずはこちらをご確認下さい。 |
info@will-ltd.co.jp
バーションアップの情報は、弊社ホームページの新着情報で通知し、各商品のページの更新履歴で更新内容を掲示致します。 |
最新バージョンのプログラムは、弊社ホームページ(http://www.will-ltd.co.jp/)のダウンロードのページよりダウンロードすることが出来ます。ダウンロードするファイルは、以下のバージョンアップの目的により異なりますのでご注意下さい。
|
各セットアップキットを利用してバーションアップをする前に、以下のことにご注意下さい。
|
MIMEOCXを利用して作成したアプリケーションの配布時のランタイムライセンスはフリーです。但し、開発ライセンスの配布はできません。 |
|
MIMEOCXを利用して作成したアプリケーションを配布する場合には、以下のファイルを添付する必要があります。( )内は推奨バージョンです。
※セットアップウィザードを使用する場合 MIMEOCXをインストールすると、自動的にOCXの依存ファイルが以下のディレクトリにインストールされます。
セットアップウィザードを実行すると自動的にアプリケーション配布時に必要なOCX(内部で利用しているOCX)と、DLLファイルがSetup.lstファイルに追加されます。 |
|
VBの文字コードはすべてUNICODEを使用しますので、VB以外のシステム(VCなど)と文字列を受け渡しする場合、文字コードを変換する必要があります。 UNICODE から ANSI へ変換 Text = StrConv(Text, vbFromUnicode) ANSI から UNICODE へ変換 Text = StrConv(Text, vbUnicode) |
|
Base64Encodeメソッドでエンコードした場合、エンコード後のデータは整形されておりません。 RFC2045 6.8.Base64 Concent-Transfer-Encodingの規定、 Base64でエンコードする場合は、以下の2種類の方法があります。 1.最初に全てのデータをメソッドに渡す方法 状況に応じて、どちらかの方法でエンコードしてください。 |
1.最初に全てのデータをメソッドに渡す方法
|
Dim src 'エンコードするデータの文字列 CRLF = ChrB$(13) & ChrB$(10) |
2.最初に1行単位でデータをメソッドに渡す方法
ここでいう1行とは、エンコード後の1行をイメージします。
エンコード後の文字数が76文字になるように、57バイトごとに区切ってメソッドを呼び出します。
エンコード後のデータには改行文字を付加します。
| Dim src 'エンコードするデータの文字列 Dim code 'エンコードされたBase64の文字列 CRLF = ChrB$(13) & ChrB$(10) src = Mime1.Base64Encode(src) length = LenB(src) tmp = '' For i = 1 To length Step 57 tmp = MidB$(src, i, 57) If LenB(tmp) > 0 Then code = code & tmp & CRLF End If Next |
|
Quoted-Printableは基本的にテキストを処理する方式です。処理する場合のQuoted-Printableの1行は、エンコード後もエンコード前も意味が変わりません。したがって、エンコード前のデータを1行ごとにエンコードします。(※ Quoted-Printableの場合、最初に全てのデータをメソッドに渡してエンコードすることはできません。) また、エンコードする際、必ず文字列をANSIに変換して渡してください。 |
|
Dim src 'エンコードするデータの文字列 CRLF = ChrB$(13) &
ChrB$(10) |
| uuencodeは、行頭にエンコードバイト数を示す文字が置かれます。この文字を生成するには、uuencodeByteメソッドにエンコードしたいデータを渡します。uuencode本体は、uuencodeLineメソッドを呼び出して生成します。また、最初の行にはファイル名やパーミッションが記述され、最後は end のみの行で終わります。基本的には、45バイト毎に区切ってエンコードすることをお勧めします。(uuencodeの場合、最初に全てのデータをメソッドに渡してエンコードすることができません。) |
|
Dim src 'エンコードするデータの文字列 CRLF = ChrB$(13) &
ChrB$(10) |
|
Base64にはエンコードデータの中に1行あたりのエンコード文字数が記述されておりません。必ず改行までの1行を渡してください。 Base64の場合、行の途中でデータを渡してしまうと、そこでpadding(穴埋め文字:「Base64エンコード規則」参照)が現われた場合と同じ処理を行います。 ※デコードは、どのデコード方式でもエンコードデータを1行ごとにメソッドに渡す必要があります。 |
|
Dim src 'デコードするBase64データの文字列 CRLF = ChrB$(13) &
ChrB$(10) |
※デコードは、どのデコード方式でもエンコードデータを1行ごとにメソッドに渡す必要があります。
|
Dim src 'デコードするQuotedPrintableデータの文字列 CRLF = ChrB$(13) &
ChrB$(10) |
uuencodeの場合、行頭にエンコード文字数が指定されているので、その文字数に満たない場合は、処理を行いません。
※デコードは、どのデコード方式でもエンコードデータを1行ごとにメソッドに渡す必要があります。
|
Dim src 'デコードするuuencodeデータの文字列 CRLF =
ChrB$(13) & ChrB$(10) |
|
MIMEOCXのバージョン情報です。アプリケーション作成者は、アプリケーションプログラムまたはマニュアルに、ここで表示される文字列を表記するようにしてください。 |
| (指定項目) | (内 容) |
| Object | MIMEOCXオブジェクトです。 |
文字列(String)
|
MIMEOCXのライセンス情報です。バージョン情報画面からいつでもライセンスの変更が可能です。トライアルライセンスから正規ライセンスに切り替えた場合、このプロパティでライセンス情報を確認してください。 |
| (指定項目) | (内 容) |
| Object | MIMEOCXオブジェクトです。 |
文字列(String)
|
EncodeMimeHeaderメソッドにおいて行の長さを78バイト(改行コードを含まず)に納める処理を行うかどうか示します。 |
| (指定項目) | (内 容) |
| Object | MIMEOCXオブジェクトです。 |
| Value | 改行を指示する長整数です。デフォルト値は1です。 次の設定値を参照してください。 |
| (値) | (説 明) |
| 1 | 行が78バイトを超えるとき直前のカンマの位置で改行します。 |
| 2 | 行が78バイトを超えるとき直前の空白の位置で改行します。 |
| 4 | 行が78バイトを超えるときその位置で改行します。 |
|
Sourceに与えられたバイト列をBase64で符号化して返します。Sourceに指定されたバイト列をBase64符号化規則で符号化します。エンコードされた文字列を戻り値に返します。空文字を入れるとエラーが発生します。 ※「プログラミング概要」の「Base64でエンコードする場合」も併せて参照してください。 |
| (指定項目) | (内 容) |
| Object | MIMEOCXオブジェクトです。 |
| Source | バイト列を指定する文字列式です。 |
| Code | エンコードされた文字列です。 |
String(文字列)
|
Sourceに与えられたBase64符号化文字列をバイト列に変換して返します。Sourceに指定されたBase64符号化文字列をBase64符号化規則でバイト列に変換します。デコードされた文字列を戻り値に返します。空文字を入れるとエラーが発生します ※「プログラミング概要」の「Base64でデコードする場合」も併せて参照してください。 |
| (指定項目) | (内 容) |
| Object | MIMEOCXオブジェクトです。 |
| Source | バイト列を指定する文字列式です。 |
| Original | デコードされた文字列です。 |
String(文字列)
|
Sourceに与えられたバイト列をQuoted-Printableで符号化して返します。Sourceに指定されたバイト列をQuoted-Printable符号化規則で符号化します。エンコードされた文字列を戻り値に返します。空文字を入れるとエラーが発生します。 ※「プログラミング概要」の「Quoted-Printableでエンコードする場合」も併せて参照してください。 |
| (指定項目) | (内 容) |
| Object | MIMEOCXオブジェクトです。 |
| Source | Quoted-Printable符号化文字列を指定する文字列式です。 |
| Code | エンコードされた文字列です。 |
String(文字列)
|
Sourceに与えられたQuoted-Printable符号化文字列をバイト列に変換して返します。Sourceに指定されたQuoted-Printable符号化文字列をQuoted-Printable符号化規則でバイト列に変換します。デコードされた文字列を戻り値に返します。空文字を入れるとエラーが発生します。 ※「プログラミング概要」の「Quoted-Printableでデコードする場合」も併せて参照してください。 |
| (指定項目) | (内 容) |
| Object | MIMEOCXオブジェクトです。 |
| Source | Quoted-Printable符号化文字列を指定する文字列式です。 |
| Original | デコードされた文字列です。 |
String(文字列)
|
Sourceに与えられたバイト列をuuencodeで符号化して返します。Sourceに指定されたバイト列をuuencode符号化規則で符号化します。戻り値に変換された文字列が設定されます。エンコードされた文字列を戻り値に返します。空文字を入れるとエラーが発生します。 ※「プログラミング概要」の「uuencodeでエンコードする場合」も併せて参照してください。 |
| (指定項目) | (内 容) |
| Object | MIMEOCXオブジェクトです。 |
| Source | バイト列を指定する文字列式です。 |
| Code | エンコードされた文字列です。 |
String(文字列)
|
uuencodeのbegin行を作成して返します。Fileで指定されたファイル名をbegin行に埋め込んで返します。このメソッドでは、begin行を指定する場合パーミッションに”600”を指定してください。以下の文字列を作成します。 Begin 600 Filename |
| (指定項目) | (内 容) |
| Object | MIMEOCXオブジェクトです。 |
| Filename | begin行に埋め込むファイル名を指定する文字列式です。 |
| Permission | パーミッションを指定する文字列式です。 |
| Begin | Uuencodeの1行目の文字列です。 |
String(文字列)
|
uuencodeのend行を作成し、返します。常に空行1行とend行を作成します。 、 end |
| (指定項目) | (内 容) |
| Object | MIMEOCXオブジェクトです。 |
| End | Uuencodeの末行の文字列です。 |
String(文字列)
|
1行に含まれるバイト数を示すuuencode文字を返します。uuencodeでは行頭に、その行に元のデータが何バイトのデータで含まれているかを示す文字が付加されます。UuEncodeByteはこの数値から文字への変換を行います。空文字を入れるとエラーが発生します。 |
| (指定項目) | (内 容) |
| Object | MIMEOCXオブジェクトです。 |
| Source | バイト列を指定する文字列式です。 |
| Num | バイト数を示すuuencode文字列です。 |
String(文字列)
|
Sourceに与えられたuudecode符号化文字列をバイト列に変換して返します。Sourceに指定されたuudecode符号化文字列をuudecode符号化規則でバイト列に変換します。 デコードされた文字列を戻り値に返します。空文字を入れるとエラーが発生します。 |
| (指定項目) | (内 容) |
| Object | MIMEOCXオブジェクトです。 |
| Source | uudecode符号化文字列を指定する文字列式です。 |
| Code | デコードされた文字列です。 |
String(文字列)
|
いわゆるMIME Headerといわれる電子メールのヘッダに日本語を置くためのエンコードをサポートします。 MIME Headerは次の書式で表されます。 charsetには各国の文字セットを指定できますが、現在の実装ではISO-2022-JPで固定です。encodingにはQエンコーディングとBエンコーディングが指定できますが、現在の実装ではBエンコーディング固定です。Sourceをエンコードした結果75文字を超える場合は、RFC2046の規定に合わせて、複数のencoded-wordに分割する必要があります。(76文字以上のエンコード文字は、動作を保証しません。)MIMEOCXは漢字コードの判定を行わないので、このメソッドの呼び出し側で文字数を限定して渡す必要があります。現在の実装では、元の文字コードがJISの場合は少なくとも24文字ごとに、SJISあるいはEUCの場合は、行を28文字ごとに切ってください。 |
| (指定項目) | (内 容) |
| Object | MIMEOCXオブジェクトです。 |
| Source | エンコードする文字列を指定する文字列式です。 |
| Header | MIMEのヘッダー文字列です。 |
String(文字列)
|
Sourceにはフォーマットとして完全なencode-wordを指定してください。通常1行分の文字列を指定すれば、完全なencoded-wordになります。この時、行末の改行文字はSourceに含めないでください。改行文字がある場合はエラーになってしまいます。また、1行の中にencoded-wordが2つ以上存在する場合1つ目のものをデコードし残りをSourceに戻します。 |
| (指定項目) | (内 容) |
| Object | MIMEOCXオブジェクトです。 |
| Source | デコードする文字列を指定する文字列式です。 |
| Original | デコードされた文字列です。 |
String(文字列)
| Base64符号化フォーマットは、3バイトを単位として、それを6ビットの符号化単位4個に分割します。 そして、これらの6ビット単位を表1に示した対応にしたがって符号化します。 |
表1:Base64の文字の割り当て
| Val | Enc | Val | Enc | Val | Enc | Val | Enc | Val | Enc |
| 0 | A | 13 | N | 26 | a | 39 | n | 52 | 0 |
| 1 | B | 14 | O | 27 | b | 40 | o | 53 | 1 |
| 2 | C | 15 | P | 28 | c | 41 | p | 54 | 2 |
| 3 | D | 16 | Q | 29 | d | 42 | q | 55 | 3 |
| 4 | E | 17 | R | 30 | e | 43 | r | 56 | 4 |
| 5 | F | 18 | S | 31 | f | 44 | s | 57 | 5 |
| 6 | G | 19 | T | 32 | g | 45 | t | 58 | 6 |
| 7 | H | 20 | U | 33 | h | 46 | u | 59 | 7 |
| 8 | I | 21 | V | 34 | i | 47 | v | 60 | 8 |
| 9 | J | 22 | W | 35 | j | 48 | w | 61 | 9 |
| 10 | K | 23 | X | 36 | k | 49 | x | 62 | + |
| 11 | L | 24 | Y | 37 | l | 50 | y | 63 | / |
| 12 | M | 25 | Z | 38 | m | 51 | z | Pad | = |
|
Base64符号化データの終わりには、元のデータの長さによって、以下の3通りの状態が起り得ます。
|
元の文字列=「Hello」
| テキスト | H | e | l | l | o |
| 16進 | 48 | 65 | 6C | 6C | 6F |
| 2進 | 01001000 | 01100101 | 01101100 | 01101100 | 01101111 |
3バイト(24ビット)ごとに取り出し、6ビットごとの4つのグループに分けます。
| H | e | l |
| 010010 00 | 0110 0101 | 01 101100 |
| 010010 | 000110 | 010101 | 101100 |
| 18 | 6 | 21 | 44 |
| S | G | V | s |
|
残りの文字を処理します。 |
| l | o | |
| 011011 00 | 0110 1111 | ?? ?????? |
| 011011 | 000110 | 1111?? | ?????? |
| 27 | 6 | 60 | |
| b | G | 8 | = |
したがって、「Hello」という文字列はBase64符号化により、「SGVsbG8=」となります。
| 元の文字列「SGVsbG8=」は、4バイトごとに取り出し、変換テーブルから数字に変換し、6ビット表現にします。その後8ビットごとにまとめます。 |
| S | G | V | s |
| 18 | 6 | 21 | 44 |
| 00010010 | 00000110 | 00010101 | 00101100 |
| 010010 | 000110 | 010101 | 101100 |
| 010010 00 | 0110 0101 | 01 101100 |
| H | e | l |
残りの文字を処理します。
| b | G | 8 | = |
| 27 | 6 | 60 | ? |
| 00011011 | 00000110 | 00111100 | ???????? |
| 0011011 | 000110 | 111100 | ?????? |
| 01101100 | 01101111 | 00?????? |
| l | o |
最後の1文字は穴埋め文字なので捨てます。
| Quoted-Printableの符号化法は、データの各バイトを、等号(=)に続けてバイト値を16進2桁で表記することで表現します。印刷可能なASCII文字(33から60までと62から126まで)の範囲の値のバイトはASCII文字もそのもので表すことも出来ます。また、Quoted-Printableは、行末(the end of line)に「空白」か「タブ」を置くことを禁止しています。その場合、それぞれ「=20」「=09」に符号化しなければなりません。Non-whitespace文字が続いている場合は、符号化しません。 |
元の文字列=「Hello」
| H | e | l | l | o | |||||
| 01001000 | 01100101 | 01101100 | 01101100 | 01101111 | |||||
| 0100 | 1000 | 0110 | 0101 | 0110 | 1100 | 0110 | 1100 | 0110 | 1111 |
| 4 | 8 | 6 | 5 | 6 | 12 | 6 | 12 | 6 | 15 |
| 3 | 7 | 5 | 4 | 5 | B | 5 | B | 5 | F |
変換後の文字列
=37=54=5B=5B=5F
但し、通常ASCII文字列をQuoted-Printable符号化することはありません。
|
uuencode符号化ファイルは次のようになります。 begin <permissions><file name> <lines of encoded data> <zero line> end 最初の行は、beginで始まり、その後にファイルのセキュリティ許可情報を符号化した番号、最後にファイル名が続きます。 begin行のあとには、符号化されたデータ行が続きます。符号化データの終わりには、長さが0の行が置かれます。uuencodeの終わりには、end行が置かれます。 begin行のセキュリティの指定は、UNIXのファイルシステムの許可ビットと同じです。8進数3桁で表示されます。たとえば、640という指定はファイルの所有者に読み書き許可を与え、同じグループに属するユーザに読み込み許可だけを与え、その他のユーザにはすべてのアクセスを許可しないという指定になります。ファイル名にはDOSの制限(大文字小文字を区別しません。長さが8+3文字まで。)は適用されません。そのため、DOSを相手にする可能性がある場合は、DOSの適当なファイル名を作り出すか、ユーザーがファイル名を指定できるようにしなければなりません。 begin行のあとには、符号化データ行が続きます。符号化データ行は、符号化されたデータのバイト数を示す文字で始まり、そのあとに符号化バイトが続きます。データの符号化方法は、3バイトを単位として、それを6ビットの符号化単位4個に分割します。ここで得られた値にスペース文字のASCII値(10進数で32)を加え、印刷可能なASCII文字を得ます。 |
元の文字列=「Hello」
| テキスト | H | e | l | l | o |
| 16進 | 48 | 65 | 6C | 6C | 6F |
| 2進 | 01001000 | 01100101 | 01101100 | 01101100 | 01101111 |
3バイト(24ビット)ごとに取り出し、6ビットごとの4つのグループに分けます。
| H | E | l |
| 010010 00 | 0110 0101 | 01 101100 |
| 010010 | 000110 | 010101 | 101100 |
| 18 | 6 | 21 | 44 |
| S | G | V | s |
残りの文字を処理します。
| l | O | |
| 011011 00 | 0110 1111 | ?? ?????? |
| 011011 | 000110 | 1111?? | ?????? |
| 27 | 6 | 60 | |
| 59 | 38 | 92 | |
| ; | & | \ |
|
uuencode符号化ファイルは次のようになります。 begin <permissions><file name> <lines of encoded data> <zero line> end 最初の行は、beginで始まり、その後にファイルのセキュリティ許可情報を符号化した番号、最後にファイル名が続きます。 begin行のあとには、符号化されたデータ行が続きます。符号化データの終わりには、長さが0の行が置かれます。uuencodeの終わりには、end行が置かれます。 begin行のセキュリティの指定は、UNIXのファイルシステムの許可ビットと同じです。8進数3桁で表示されます。たとえば、640という指定はファイルの所有者に読み書き許可を与え、同じグループに属するユーザに読み込み許可だけを与え、その他のユーザにはすべてのアクセスを許可しないという指定になります。ファイル名にはDOSの制限(大文字小文字を区別しません。長さが8+3文字まで。)は適用されません。そのため、DOSを相手にする可能性がある場合は、DOSの適当なファイル名を作り出すか、ユーザーがファイル名を指定できるようにしなければなりません。 begin行のあとには、符号化データ行が続きます。符号化データ行は、符号化されたデータのバイト数を示す文字で始まり、そのあとに符号化バイトが続きます。データの符号化方法は、3バイトを単位として、それを6ビットの符号化単位4個に分割します。ここで得られた値にスペース文字のASCII値(10進数で32)を加え、印刷可能なASCII文字を得ます。 |
(Ver 1.00)
MIMEエンコードサンプルです。
左のフレームにエンコードするファイルをドロップすると、
右のフレームにBase64方式でエンコードされたデータが表示されます。
(Ver 1.00)
MIMEデコードサンプルです。
エンコードされたデータを上段のテキストボックスに入力し、エンコード方式を選択して「表示」ボタンをクリックしてください。下段にデコードされたデータが表示されます。
「ファイルに保存」ボタンで、デコードしたデータを指定したディレクトリに保存することができます。
株式会社ウィル
Copyright 1998-2002 WILL Corporation. All rights reserved